In this post, we'll use data from a tensile test to build a stress strain curve with Python and Matplotlib.
A tensile test is a type of mechanical test performed by engineers used to determine the mechanical properties of a material. Engineering metal alloys such as steel and aluminum alloys are tensile tested in order to determine their strength and stiffness. Tensile tests are performed in a piece of equipment called a mechanical test frame.

After a tensile test is complete, a set of data is produced by the mechanical test frame. Using the data acquired during a tensile test, a stress-strain curve can be produced.
In this post, we will create a stress-strain curve (a plot) from a set of tensile test data of a steel 1045 sample and an aluminum 6061 sample. The stress strain curve we construct will have the following features:
- A descriptive title
- Axes labels with units
- Two lines on the same plot. One line for steel 1045 and one line for aluminum 6061
- A legend
Install Python¶
We are going to build our stress strain curve with Python and a Jupyter notebook. I suggest engineers and problem-solvers download and install the Anaconda distribution of Python. See this post to learn how to install Anaconda on your computer. Alternatively, you can download Python form Python.org or download Python the Microsoft Store.
Install Jupyter, NumPy, Pandas, and Matplotlib¶
Once Python is installed, the next thing we need to do is install a couple of Python packages. If you are using the Anaconda distribution of Python, the packages we are going to use to build the plot: Jupyter, NumPy, Pandas, and Matplotlib come pre-installed and no additional installation steps are necessary.
However, if you downloaded Python from Python.org or installed Python using the Microsoft Store, you will need to install install Jupyter, NumPy, Pandas, and Matplotlib separately. You can install Jupyter, NumPy, Pandas, and Matplotlib with pip (the Python package manager) or install theses four packages with the Anaconda Prompt.
If you are using a terminal and pip, type:
> pip install jupyter numpy pandas matplotlib
If you have Anaconda installed and use the Anaconda Prompt, type:
> conda install jupyter numpy pandas matplotlib
Download the data and move the data into the same folder as the Jupyter notebook¶
Next, we need to download the two data files that we will use to build our stress-strain curve. You can download sample data using the links below:
After these .xls files are downloaded, both .xls files need to be moved into the same folder as our Jupyter notebook.
Import NumPy, Pandas, and Matplotlib¶
Now that our Jupyter notebook is open and the two .xls data files are in the same folder as the Jupyter notebook, we can start coding and build our plot.
At the top of the Jupyter notebook, import NumPy, Pandas and Matplotlib. The command %matplotlib inline is included so that our plot will display directly inside our Jupyter notebook. If you are using a .py file instead of a Jupyter notebook, make sure to comment out %matplotlib inline as this line is not valid Python code.
We will also print out the versions of our NumPy and Pandas packages using the .__version__ attribute. If the versions of NumPy and Pandas prints out, that means that NumPy and Pandas are installed and we can use these packages in our code.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
print("NumPy version:",np.__version__)
print("Pandas version:",pd.__version__)
Ensure the two .xls data files are in the same folder as the Jupyter notebook¶
Before we proceed, let's make sure the two .xls data files are in the same folder as our running Jupyter notebook. We'll use a Jupyter notebook magic command to print out the contents of the folder that our notebook is in. The %ls command lists the contents of the current folder.
%ls
We can see our Jupyter notebook stress_strain_curve_with_python.ipynb as well as the two .xls data files aluminum6061.xls and steel1045.xls are in our current folder.
Now that we are sure the two .xls data files are in the same folder as our notebook, we can import the data in the two two .xls files using Panda's pd.read_excel() function. The data from the two excel files will be stored in two Pandas dataframes called steel_df and al_df.
steel_df = pd.read_excel("steel1045.xls")
al_df = pd.read_excel("aluminum6061.xls")
We can use Pandas .head() method to view the first five rows of each dataframe.
steel_df.head()
al_df.head()
We see a number of columns in each dataframe. The columns we are interested in are FORCE, EXT, and CH5. Below is a description of what these columns mean.
- FORCE Force measurements from the load cell in pounds (lb), force in pounds
- EXT Extension measurements from the mechanical extensometer in percent (%), strain in percent
- CH5 Extension readings from the laser extensometer in percent (%), strain in percent
Create stress and strain series from the FORCE, EXT, and CH5 columns¶
Next we'll create a four Pandas series from the ['CH5'] and ['FORCE'] columns of our al_df and steel_df dataframes. The equations below show how to calculate stress, $\sigma$, and strain, $\epsilon$, from force $F$ and cross-sectional area $A$. Cross-sectional area $A$ is the formula for the area of a circle. For the steel and aluminum samples we tested, the diameter $d$ was $0.506 \ in$.
strain_steel = steel_df['CH5']*0.01
d_steel = 0.506 # test bar diameter = 0.506 inches
stress_steel = (steel_df['FORCE']*0.001)/(np.pi*((d_steel/2)**2))
strain_al = al_df['CH5']*0.01
d_al = 0.506 # test bar diameter = 0.506 inches
stress_al = (al_df['FORCE']*0.001)/(np.pi*((d_al/2)**2))
Build a quick plot¶
Now that we have the data from the tensile test in four series, we can build a quick plot using Matplotlib's plt.plot() method. The first x,y pair we pass to plt.plot() is strain_steel,stress_steel and the second x,y pair we pass in is strain_al,stress_al. The command plt.show() shows the plot.
plt.plot(strain_steel,stress_steel,strain_al,stress_al)
plt.show()

We see a plot with two lines. One line represents the steel sample and one line represents the aluminum sample. We can improve our plot by adding axis labels with units, a title and a legend.
Add axis labels, title and a legend¶
Axis labels, titles and a legend are added to our plot with three Matplotlib methods. The methods are summarized in the table below.
| Matplotlib method | description | example |
|---|---|---|
plt.xlabel() |
x-axis label | plt.xlabel('strain (in/in)') |
plt.ylabel() |
y-axis label | plt.ylabel('stress (ksi)') |
plt.title() |
plot title | plt.title('Stress Strain Curve') |
plt.legend() |
legend | plt.legend(['steel','aluminum']) |
The code cell below shows these four methods in action and produces a plot.
plt.plot(strain_steel,stress_steel,strain_al,stress_al)
plt.xlabel('strain (in/in)')
plt.ylabel('stress (ksi)')
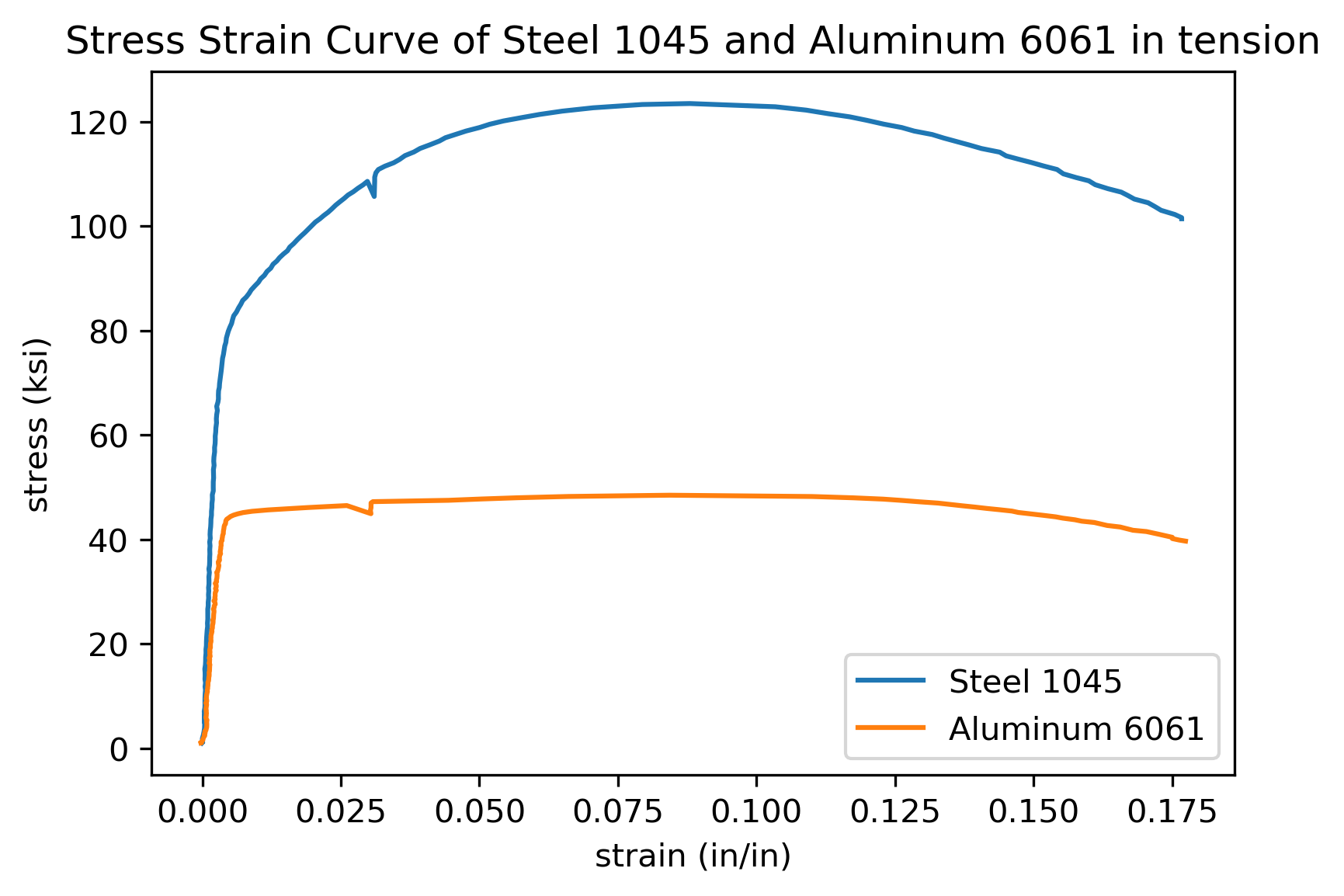
plt.title('Stress Strain Curve of Steel 1045 and Aluminum 6061 in tension')
plt.legend(['Steel 1045','Aluminum 6061'])
plt.show()

The plot we see has two lines, axis labels, a title and a legend. Next we'll save the plot to a .png image file.
Save the plot as a .png image¶
{kind=link}
Now we can save the plot as a .png image using Matplotlib's plt.savefig() method. The code cell below builds the plot and saves an image file called stress-strain_curve.png. The argument dpi=300 inside of Matplotlib's plt.savefig() method specifies the resolution of our saved image. The image stress-strain_curve.png will be saved in the same folder as our running Jupyter notebook.
plt.plot(strain_steel,stress_steel,strain_al,stress_al)
plt.xlabel('strain (in/in)')
plt.ylabel('stress (ksi)')
plt.title('Stress Strain Curve of Steel 1045 and Aluminum 6061 in tension')
plt.legend(['Steel 1045','Aluminum 6061'])
plt.savefig('stress-strain_curve.png', dpi=300, bbox_inches='tight')
plt.show()
Our complete stress strain curve contains two lines, one for steel and one for aluminum. The plot has axis labels with units, a title and a legend. A copy of the plot is now saved as stress-strain_curve.png in the same folder as our Jupyter notebook.
Summary¶
In this post, we built a stress strain curve using Python. First we installed Python and made sure that NumPy, Pandas, Matplotlib and Jupyter were installed. Next we opened a Jupyter notebook and moved our .xls data files into the same folder as the Jupyter notebook. Inside the Jupyter notebook we entered code into a couple different code cells.
In the first Jupyter notebook code cell, we imported NumPy, Pandas, and Matplotlib and printed our their versions. In the next code cell, we saved the data from two .xls data files into two Pandas dataframes. In the third code cell, we created Pandas series for stress and strain from the columns in the dataframes. In the final code cell we built our stress strain curve with Matplotlib and saved the plot to a .png image file.