I had one of those "Automate the Boring Stuff" problems this week. How do you convert a multi-page PDF into a folder of images? One image for each page in the PDF? Read on to see how to solve this problem with Python.
The Problem
So here is the basic problem:
Convert a multi-page PDF into a directory of images
We're going to solve this problem with Python.
Install Python
If you don't have Python installed yet, I suggest you install the Anaconda distribution of Python. See this post to learn how to install Anaconda on your computer. Alternatively, you can download Python form Python.org or download Python from the Microsoft Store.
Create and virtual environment and install pdf2image
Before we start writing Python code, it is a good idea to create a new virtual environment. A virtual environment is an isolated installation of Python that is separate from other Python installations running on your computer. See this post to learn how to create a virtual environment with the Anaconda Prompt.
To create a new Python virtual environment, open the Anaconda Prompt and type the following commands. Note the prompt sign > is included to indicate the prompt, not a character you should type. The -n pdf portion of the command denotes the name of the virtual environment. python=3.7 ensures Python Version 3.7 is installed into the pdf virtual environment.
> conda create -n pdf python=3.7
Type y for yes when prompted. Before we install any packages into the pdf virtual environment, it needs to be activated. Activate the pdf virtual environment with the command below. Note that when the pdf virtual environment is active, (pdf) is shown in parenthesis before the prompt.
> conda activate pdf
(pdf)>
Install img2pdf and poppler
Next, we need to install the poppler package using conda and the pdf2image package using pip. The -c conda-forge portion of the conda install command indicates poppler will be installed from the conda-forge channel of packages.
(pdf)> conda install -c conda-forge poppler
(pdf)> pip install pdf2image
Imports
Alright, it's time to write the code.
Use a code editor like VS Code or PyCharm to create a new file called pdf.py.
At the top of the file, import the convert_from_path function from the pdf2image package and the pdf2image exceptions.
# pdf.py
from pdf2image import convert_from_path
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
The code
Below is the code to convert a PDF named myfile.pdf to multiple .png images. Save this code below the import lines.
images = convert_from_path('myfile.pdf')
for i, image in enumerate(images):
fname = "image" + str(i) + ".png"
image.save(fname, "PNG")
Run the code
Put a PDF file in the same folder as the code. Make sure the PDF file has the same name as used in the code above. I called my PDF file myfile.pdf. If your PDF file has a different name, either re-name the PDF or use a different file name in the code above
├───pdf
│ ├───pdf.py
│ └───myfile.pdf
Our pdf.py script can be run from the Anaconda Prompt. Make sure the (pdf) environment is active before the script is run.
(pdf)> python pdf.py
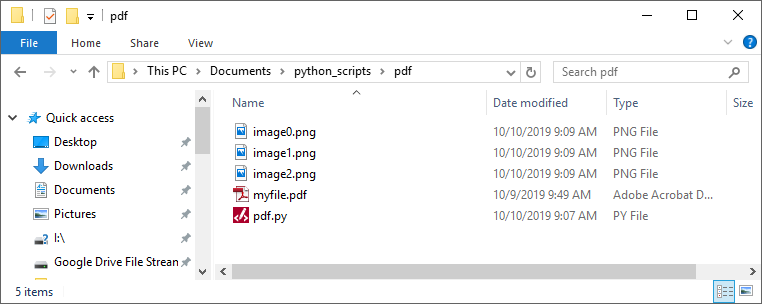
When the script finishes, you should see images in the same folder as your pdf.py script and myfile.pdf PDF file. My PDF had three pages, so three .png image files were created.
Summary
In this post, we used a Python package called pdf2image to convert a PDF file into a directory full of images. Big thanks to the maintainers of pdf2image for making such a useful package!
The complete Python script is below:
# pdf.py
"""
A Python script to convert a multi-page PDF to a directory of images
Uses the pdf2image package
"""
from pdf2image import convert_from_path
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
images = convert_from_path('myfile.pdf')
for i, image in enumerate(images):
fname = 'image'+str(i)+'.png'
image.save(fname, "PNG")